很久以前寫過一篇基本的 mongodb group 語法的基本介紹,在這些年間也持續跟 mongodb 持續纏鬥無法自拔…,對他又愛又恨,雖然超想拔掉他,但是從用途/功能性上卻無法找到他的取代品。
如今已經面臨要開始用他來 JOIN 了,感覺這毒是越吸越重了..XD 讓我們繼續看下去..
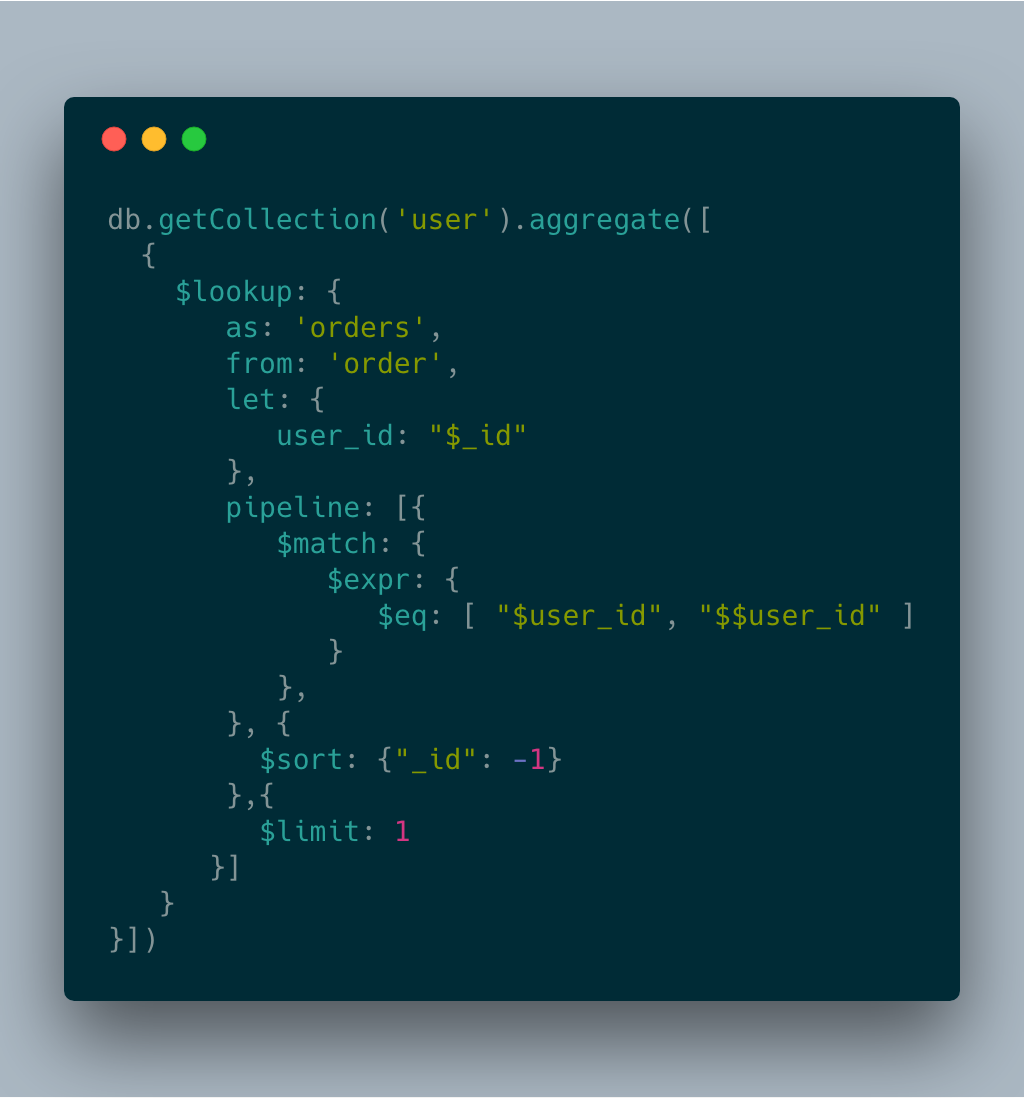
我們今天試著從 3.2 開始 aggregate 新支援的語法 $lookup 搭配 3.6 開始的 lookup pipeline 來解決我們需要 LEFT JOIN 的問題。
Continue reading…
