很久以前寫過一篇基本的 mongodb group 語法的基本介紹,在這些年間也持續跟 mongodb 持續纏鬥無法自拔…,對他又愛又恨,雖然超想拔掉他,但是從用途/功能性上卻無法找到他的取代品。
如今已經面臨要開始用他來 JOIN 了,感覺這毒是越吸越重了..XD 讓我們繼續看下去..
我們今天試著從 3.2 開始 aggregate 新支援的語法 $lookup 搭配 3.6 開始的 lookup pipeline 來解決我們需要 LEFT JOIN 的問題。
先複習一下,所有 mysql 跟 mongodb syntax 的 mapping,官方已經有一個不錯的文件快速幫助參照要怎麼把 SQL 轉換成 mongodb query
先來一個範例資料吧,現在有兩個 collection 使用者 user 跟訂單 order
user
| _id | name |
|-----|--------|
| 1 | mlwmlw |
| 2 | wawa |
| 3 | hap |
order
| _id | user_id | amount |
|-----|---------|--------|
| 1 | 1 | 300 |
| 2 | 2 | 123 |
| 3 | 1 | 500 |如果用 SQL 的語法,要取得使用者的每筆訂單會這樣查詢
SELECT user._id, user.name, sum(order.amount) from user
LEFT JOIN order on user._id = order.user_id如果使用 mongodb 的 aggregate framework 的話則是透過從 3.2 開始支援的 lookup
db.getCollection('user').aggregate([
{$lookup:
{
as: 'orders',
from: 'order',
localField: "_id",
foreignField: "user_id"
}
}])對應到 SQL 來看就蠻容易理解的,只是查詢出來的結構會是有多一個 orders 的 array 出現,不像是 SQL 被拆解成數筆資料,如果想要得到跟 SQL 一樣的結果也是可以透過 $unwind 來達成
//result
[
{
"_id" : 1,
"name" : "mlwmlw",
"orders" : [
{
"_id" : 1,
"user_id" : 1,
"amount" : "300"
},
{
"_id" : 3,
"user_id" : 1,
"amount" : 500
}
]
},
{
"_id" : 2.0,
"name" : "wawa",
"orders" : [
{
"_id" : 2,
"user_id" : 2,
"amount" : 123
}
]
},
{
"_id" : 3.0,
"name" : "hap",
"orders" : []
}
]這樣連帶造成的問題是 JOIN 起來的資料量有可能會因為 order 的數量不斷增加而變多,超過 BSON 單筆 16MB 的限制,資料就會查不出來了,會噴出如下錯誤
Aggregate $lookup Total size of documents in matching pipeline exceeds maximum document size這個時候 3.6 開始支援的 $lookup pipeline 就可以解決這個問題了,就像在 SQL 中,你可以透過 JOIN 的 on 多增加一些條件,來減少需要被 JOIN 的資料量,pipeline 就是讓你在 lookup 重新獲得 aggregate 的能力
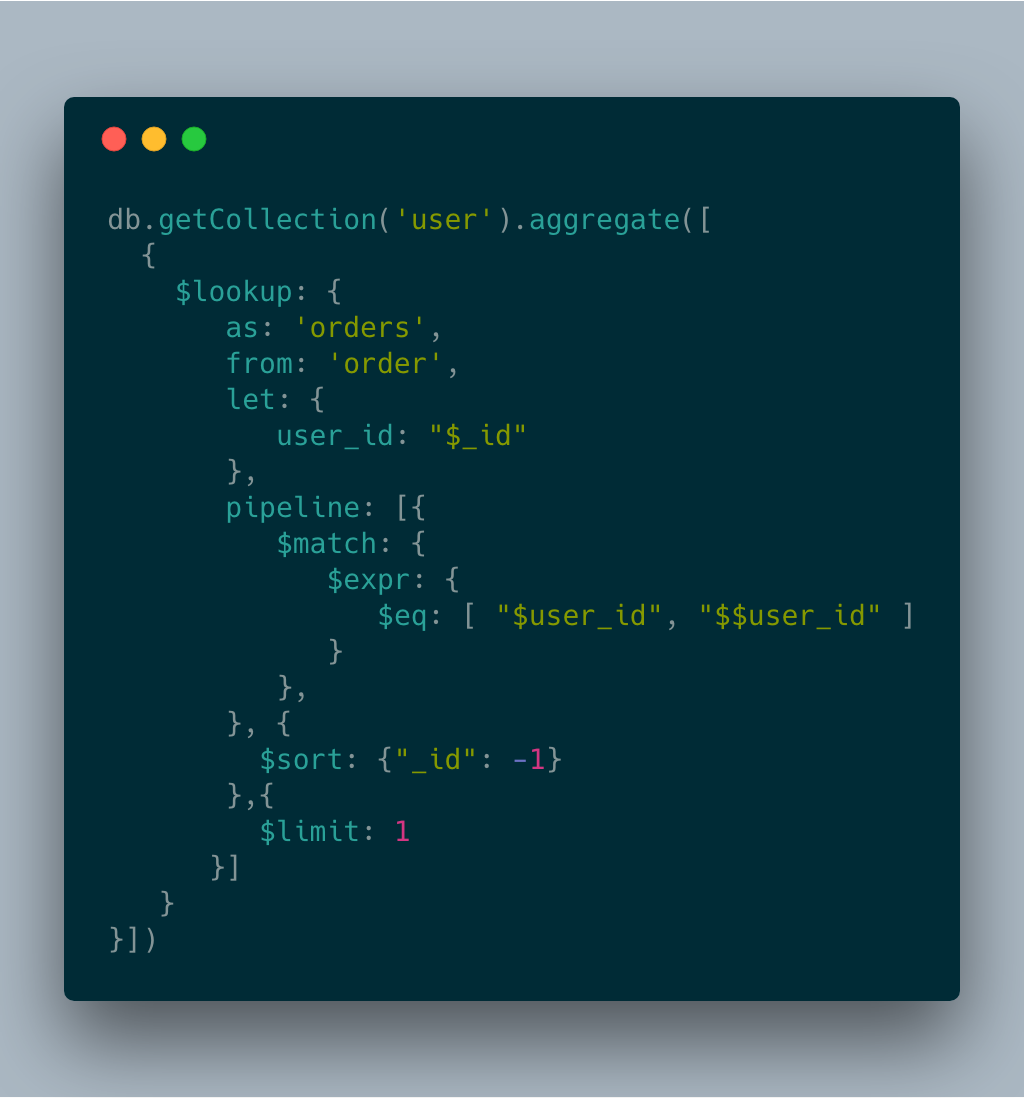
例如想要取得每一個使用者最新一筆訂單,可以改成
db.getCollection('user').aggregate([
{$lookup:
{
as: 'orders',
from: 'order',
let: {
//order.user_id
order_user_id: "$user_id"
},
pipeline: [{
$match: {
$expr: {
// on user._id = order.user_id
$eq: [ "$_id", "$$order_user_id" ]
}
},
}, {
$sort: {"_id": -1}
},{
$limit: 1
}]
}
}])透過 pipeline 的 $match 來作為 on 的條件,搭配 pipeline 的 aggregate 能力,可以在做任何 $sort, $group 等語法,來讓最後 JOIN 進 document 的內容選擇只要你需要用到的資料
結論
就如同 SQL 有子查詢的能力一般,在這個版本上,幾乎可以滿足 90% 以上 SQL 的查詢能力了,Pipeline 的彈性甚至超越 SQL( Declarative programming),因為更偏向指令、流程(Imperative programming) 的描述方式一些, 只是這種混種品寫起來會很想死而已XD
之前有試用過 Mongodb 的 bi-connector,他就是幫你把 SQL 轉成 mongodb 的 aggregate,解決這種痛苦的窘境,但是當初試用的時候還在 3.2 的版本的關係,其隨便一句 SQL 就能跑到要崩潰都還出不來,也不見得有辦法建立索引改進。
如今看來 Mongodb 為了朝向大眾市場,看得出來很努力在新的版本解決這些問題,說不定有一天 Mongodb 預設裝起來就能透過 SQL 來 Query 也說不定呢,就像 BigQuery 一樣,因為原本語法不是標準 SQL,所以改進起來也沒有包袱,一個版本一個版本都可以有革命性的變革,只是看起來很像是數十年前 SQL 剛被標準化時的發展軌跡呀
參考資料
官方的 lookup 說明文件,有更多範例喔 https://docs.mongodb.com/manual/reference/operator/aggregation/lookup/